Open Knowledge for the People
We are very familiar with the open source movement as coders and its phenomenal success has been entirely transforming our planet.
In the last decade we have seen open source software activity skyrocket and even at commercial level open source alternatives have been replacing proprietary products with a close development environment. This is obviously the direction to go for computer science but we are now seeing more synergies than computer science.
Open Science works with the same philosophy and dynamics as Open Source, but it covers all things science. Another term Open Research or Open Scholarship are more common in social and human sciences as well as art domains.
Papers with Code
If you are interested in Machine Learning and AI, you might already know Papers with Code, an Open Machine Learning platform that hosts Machine Learning papers with code and evaluation tables, about page here.
This might seem as a no brainer to share Open Computer Science Research with a convenient showcase platform but as we are still de-learning our old ways of hoarding knowledge it took some time for more traditional domains and entities to follow suit.
If you are active or interested in Machine Learning definitely check out the papers shared on Papers with Code.
Arxiv.org
Arxiv on the other hand is a an open-access archive and free distribution service for scholarly articles and research results founded by Cornell University.
Common domains of edge-cutting papers that it hosts are:
- physics,
- mathematics,
- computer science,
- quantitative biology,
- quantitative finance,
- statistics,
- electrical engineering
- economics
If you check out Arxiv.org each field has very interesting sub-categories and specializations. For instance, these are the sub-topics of Computer Science:
- Artificial Intelligence;
- Computation and Language;
- Computational Complexity;
- Computational Engineering,
- Finance and Science;
- Computational Geometry;
- Computer Science and Game Theory;
- Computer Vision and Pattern Recognition;
- Computers and Society;
- Cryptography and Security;
- Data Structures and Algorithms;
- Databases;
- Digital Libraries;
- Discrete Mathematics;
- Distributed, Parallel, and Cluster Computing;
- Emerging Technologies;
- Formal Languages and Automata Theory;
- General Literature;
- Graphics;
- Hardware Architecture;
- Human-Computer Interaction;
- Information Retrieval;
- Information Theory;
- Logic in Computer Science;
- Machine Learning;
- Mathematical Software;
- Multiagent Systems;
- Multimedia;
- Networking and Internet Architecture;
- Neural and Evolutionary Computing;
- Numerical Analysis;
- Operating Systems;
- Other Computer Science;
- Performance;
- Programming Languages;
- Robotics;
- Social and Information Networks;
- Software Engineering;
- Sound;
- Symbolic Computation;
- Systems and Control
Papers on Arxiv do go through some moderation and you have to be endorsed by an Arxiv publisher to be able to publish on Arxiv at first place. However, Arxiv papers are not peer-reviewed. This has some implications, which are not necessarily positive or negative:
- Arxiv papers can be faster than traditional research papers since there isn’t the same amount of rigorous reviewing steps.
- This also means they can have more mistakes than traditional papers
- Arxiv papers are open to public for free. This means knowledge is shared freely without the paywalls people hit via traditional academia resources.
- Arxiv papers get lots of public recognition and people can quickly start improving them, working on them or building on them.
- Arxiv can be considered as a preliminary route before publishing through the traditional channels. Arxiv doesn’t cancel the opportunity for publishing a more complete research paper later but it rather enables a fast and quick feedback and free usage.
Arxiv with Code
Now, the news is that as of early October 2020, Arxiv implemented a code section in collaboration with “Papers with Code”. This means scientists and researchers can conveniently add the code involved in their paper directly on a Code Tab that’s added in the paper’s page.
This step might seem trivial to some people but it’s actually very big deal as it enables and encourages more and open sharing in terms of code.
This kind of practical innovation boosts overall activity and the quality of results in long term. We have been seeing it happen with open source work. Today, open source software reached a mind-blowing level.
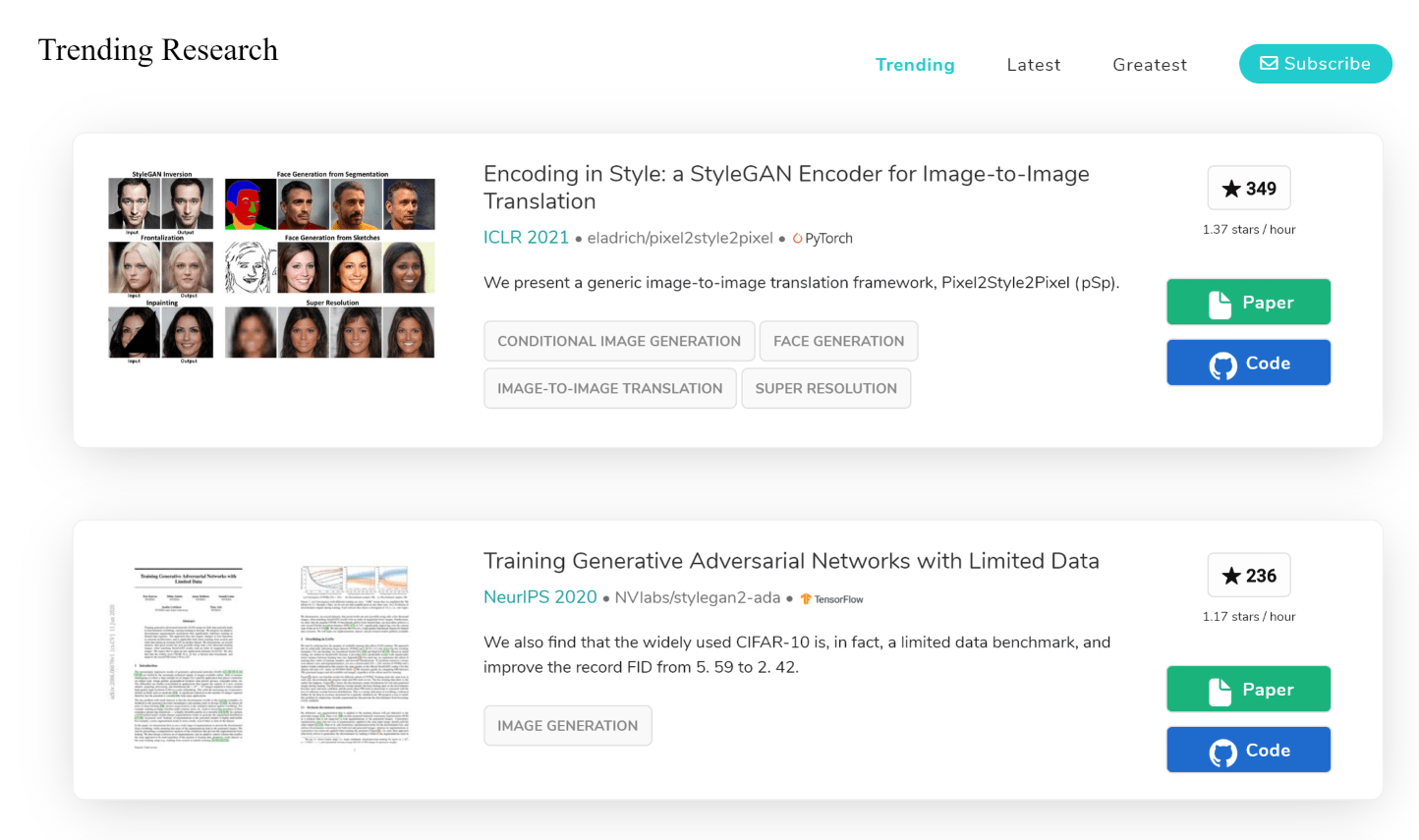
For example, if you go to this qualifying paper: Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation, you can see that under the code tab its code is published and can be directly accessible through its Github link.
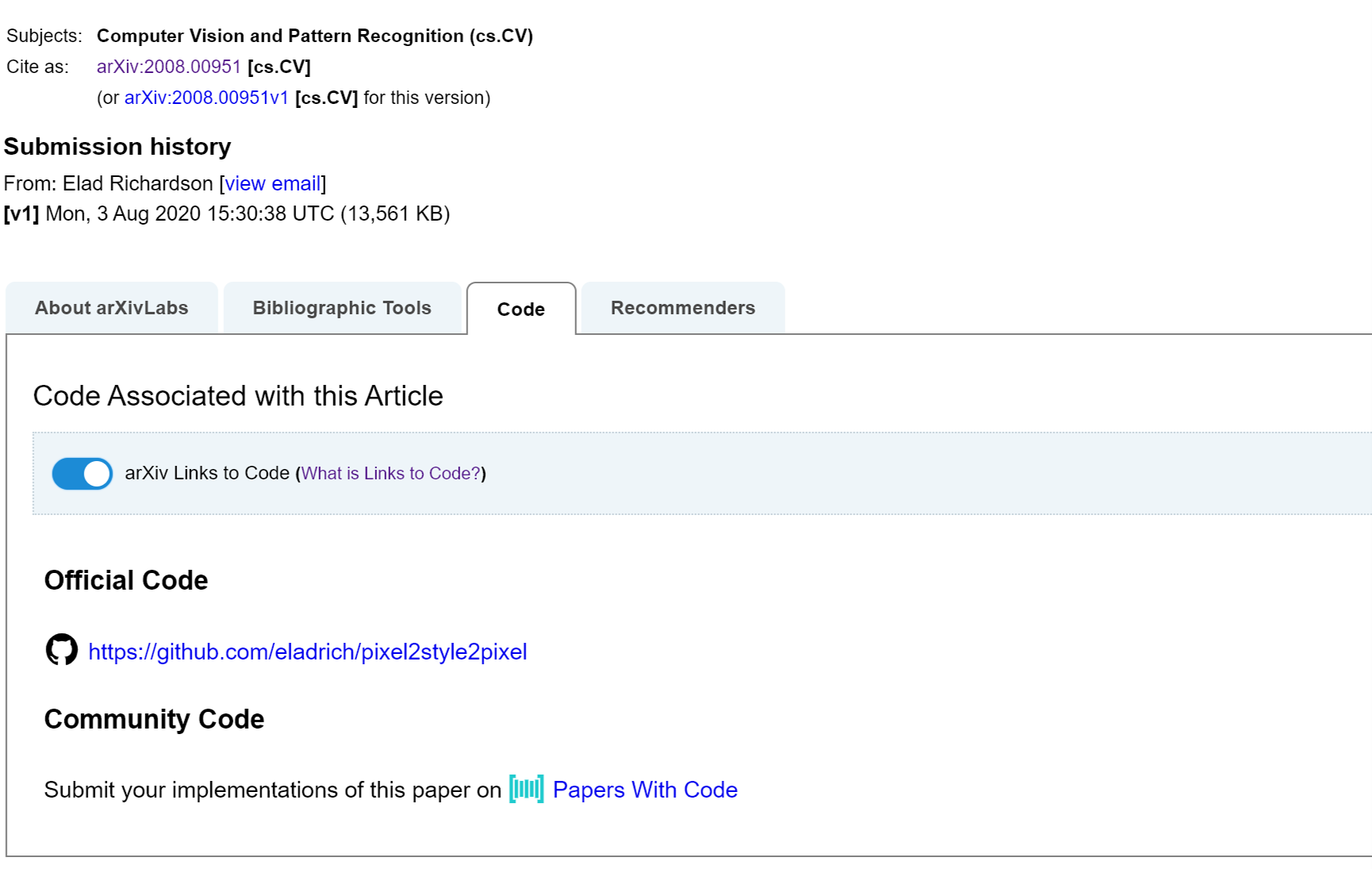
This is incredible not only for CS or AI papers but papers in all fields and branches since coding is becoming a major enabler and amplifier of intellectual work. As more and more research is expected to include some form of code work in it this is a wise move from Cornell’s non-profit organization.
Conclusion
Arxiv’s move will not only make it easier to share research code but it will also make it easier to re-apply the work, experiment the same results, contribute to the existing work and come up with improvements in a more efficient fashion that hasn’t existed before.
Also, authors of papers could have been less reluctant to share the full code work due to restrictions before especially if the domain is not directly related to computer science or software development. This new feature can encourage all the code involved in a paper to be shared conveniently.
Let’s hope that Open Source philosophy will continue to influence more Open Science work and research from all aspects.