
- Python Lesson: APIs with Python
- Python Exercise: APIs with Python
- Mars Weather API
- Dog Pics API
- Sunrise and Sunset API
- Name Generator API
- Space Launch Data API
- Earthquake Data API
- Mars Rover Images API
- Plant Info API
- Special Numbers API
- UK Police Data API
- Nasa Space Image API
- Cocktail Database API
- Official Jokes API
- Chuck Norris Jokes API
- Electric Vehicle Charge Map
- Listing Available OpenAI Models
- ChatGPT API Tutorial
- GPT-4 API Tutorial
- OpenAI Whisper API Tutorial
OpenAI Whisper API : Quick Guide
OpenAI announced Whisper API recently alongside the paradigm shifter ChatGPT API.
Whisper API’s enormous capabilities has been masked with the ChatGPT a little bit however this API will see lots of AI use cases in solo mode as well as combined with the other models and modalities.
In this tutorial, we will explain OpenAI’s Whisper and how it can be best harnessed with the API technology using the popular programming language Python and its libraries. We will make a few Whisper API examples and demonstrate its transcriptions and translations API end points with intuitive use cases of this powerful AI technology that’s available right now.
1- OpenAI Whisper API : Quick Guide
It’s always exciting to see advancements in the world of artificial intelligence, and the introduction of GPT-4 is surely a monumental milestone in the history of AI. With its ability to process image inputs, generate more dependable answers, produce socially responsible outputs, and handle queries more efficiently, this model looks set to revolutionize the field of natural language processing.
Robust Speech Recognition via Large-Scale Weak Supervision is the research paper authored by AI scientists Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever whom introduced OpenAI Whisper.
Additionally, whisper is an open source model which can be analyzed, downloaded, developed on and used for FREE.
As a Python programmer, I’m eager to see how this latest development will further enhance our ability to interact with machines in a meaningful and efficient way.
Whisper’s Transformer Architecture Explained
On the 4th page of the research paper, OpenAI’s Whisper model which is based on Google Research’s Transformer research paper is explained simply and elegantly. As usual in transformer AI applications, we are seeing the following layers clearly:
- Input layer: In speech-to-text applications based on transformers, input layer consists of audio with speech.
- Encoder layers: In a nutshell, sinusodial positional encoder layers which consists of encoder blocks, analyze audio in 30 second chunks and extract positional information related to speech and work with them within the realm of human language structures.
The input layer reads the speech signal as a series of data points and converts it to a sequence of vectors, which are fed into the first encoder layer. In this layer, the input vectors are processed and transformed into a set of feature maps, which contains the most relevant information present in the speech input.
The subsequent encoder layers repeat this process, with each layer building on the previous one to extract further information from the speech input until the final layer produces the transcription output. - Decoder layers: Decoder layers play role in the accurate conversion of audio data to tokens. After the encoder layers, the decoder layers come in play. Herein, the decoder layers attend to the words generated by the encoder and generate the transcription of the speech.
- Output layer: In whisper’s case, output layer consists of tokens which consists of logical word and punctuation structures. You can familiarize yourself with OpenAI models’ token calculations.
AI development using OpenAI’s Whisper model and Python is rather straightforward. Model can be access through API calls to its API Endpoints: Transcriptions & Translations.
Let’s get to the practical section of our tutorial and create a few simplistic Python scripts for demonstration and inspiration purposes. You can refer to Holypython’s Learn OpenAI’s Official ChatGPT API : Comprehensive Developer Guide (AI 2023) article.
Whisper API Python Example
Let’s work on the “I’m a cow song“. This funny video about cows has 23M videos on Youtube and is published under Creative Commons license. It can be downloaded to test our model’s speech-to-text capabilities. Use this Download Youtube Videos with Python tutorial or any other tool you’d like.
Also, the song’s lyrics are pronounced in a unique way that might be hard to understand, so it’s a good first test for our model.
We will use openai library so it needs to be installed (if not installed yet) and imported.
- It can be installed as:
pip install openai(might differ based on your OS setup) - It can be imported as:
import openai(see below)
For the authorization bit we will employ openai’s api_key method. It entails of simply using openai.api_key and passing the key obtained from the platform.openai.com account. (There is a menu called something like View OpenAI API Keys.)
import openai
OPENAI_API_KEY = 'YOUR_OPENAI_KEY'
openai.api_key = OPENAI_API_KEY
Once you’re done with the openai library and openai.api_key steps, you can conveniently use the .transcribe() method from the Audio class using openai library.
openai.Audio.transcribe(model="whisper-1", file=file)
We will pass two required parameters to the .transcribe method, these are model and path of audio file.
file= open("home/moomoo.mp3", "rb")
transcript = openai.Audio.transcribe(model="whisper-1", file=file)
print(transcript)
In the Python code above we are utilizing the openai.Audio.transcribe() method with the required parameters model and file. Below you can see a list of parameters that can be used with Whisper API.
Having a good grasp of these parameters can be important to fine tune the AI model and create the best possible user experiences. But first let’s check out the results of our simplistic example.
Here is the response.
Whisper API Output:
{
“text”: “I’m a cow, I’m a cow, look at me, look at me I’m a cow, I’m a cow, look at me, look
me, cause they need me Farmers milk me, and they feed me People eat me, children love me, alth
meat, I have big thighs And wow, I am so fat A few months later… Sooooo… I’m a cow, I’m a
}
Whisper API Parameters
file
The path and name of the file to be transcribed or translated. File formats can be mp3, mp4, mpeg, mpga, m4a, wav, or webm. File is a required parameter.
model
The name of the AI model that’ll be used. Currently only available speech-to-text model from OpenAI is whisper-1. Model is a required parameter.
prompt
Prompt is a guidance that can be provided to the AI model as text. This creates an opportunity to have a say on the model’s style and refrain it from taking certain actions. It can be very useful for specialized applications.
response_format
This is the response format of the model. It is json by default. Other available formats are text, srt, verbose_json, or vtt which is convenient.
temperature
Used for narrowing down the focus of AI model and make it more deterministic or the opposite. It takes values between 0 and 1. The value given by default is 0 and while values near 0 will result in highly focused AI output, values near 1 will introduce randomness to the results.
language
Used for providing the language of the audio which results in both improved performance (reduced latency) and accuracy (reduced error rate).
near human-level speech recognition, open-sourced:https://t.co/eeuTfXJkwy
(check out the examples, i find them difficult)
— Sam Altman (@sama) September 21, 2022
Whisper was announced by Sam Altman in the last quarter of 2022. Speech-to-text will be a crucial step in the near future advancements of multimodal AI and possibly on the way to Artificial General Intelligence as it provides an auditory bridge between the AI and human speech. We have an interesting article if you are curious about the history of speech-to-text technology.
In simpler words, with this technology you can talk to AI or you can make AI listen to other products of human speech such as conversations, podcasts, debates, commercials , historical speeches, music videos, news and movies.
Open Sourced Whisper vs. OpenAI Whisper API
I think it’s important to make a clear distinction about two different methods of how Whisper can be implemented in projects.
Open source whisper is the trained whisper models that are also published as open source by OpenAI. OpenAI doesn’t do this for all of its models so it’s a great privilege to be able to actually download whisper models.
That being said, downloading AI models, creating special environments and dealing with the implications of hosting the models by oneself isn’t the ideal route for every developer. It can be less practical and even more costly due to resources, cybersecurity and professional supervision required.
That’s where the Whisper’s API endpoints come in and this tutorial mostly focuses on implementation of that technology. OpenAI Whisper API is the service through which whisper model can be accessed on the go and its powers can be harnessed for a modest cost ($0.006 per audio minute) without worrying about downloading and hosting the models.
It’s good to be aware of the difference in case different model names and features come up.
Whisper vs ChatGPT
Whisper is able to carry out speech to text transformations. Although it can be perfectly fine in solo use cases with audio and speech transcriptions and translations, it also has the potential to compliment AI models with different modalities such as ChatGPT’s GPT3.5-turbo and GPT4.
Whisper’s Modality
| OpenAI Whisper Modality Vs. ChatGPT | |
|---|---|
| Whisper-1 | speech-to-text |
| GPT-3.5-Turbo | text-to-text only |
| GPT-4 | text-to-text image-to-text |
Whisper Pricing
Whisper API can be considered on the cheap side. With $0.006 per 1-minute audio processing, you slightly more than 2,5 hours of audio processing for $1 US.
| OpenAI Whisper Pricing | |
|---|---|
| Whsiper-1 | $0.006 per 1-minute audio |
Although current pricing of whisper is quite competitive as is, I believe there might be a price reduction in the future similar to what happened to GPT models. Gpt-3.5-turbo came with a 10X (or 30X depending on the time frame) price improvement although it’s a superior model compared to previous gpt-3.
Models & API: API Endpoints of Whisper
Whisper-1 model that’s used by the Whisper API uses Transcriptions or Translations endpoints depending on the use case. Model name can be assigned as whisper-1 and currently that is the only option through the API. Near the bottom of this page you can see open source versions of the whisper model but they won’t work through the official Whisper API service.
Transcriptions
- model = whisper-1 (default choice)
To use the transcription method we need to POST to https://api.openai.com/v1/audio/transcriptions. POST request gets handled automatically when openai library is used in Python.
Translations
- model = whisper-1 (default choice)
Audio File Size: Whisper can handle up to 25Mb at once.
Whisper’s current model whisper-1 comes with an audio file size limit of 25Mb.
whisper-1: 25Mb- new-whisper-model: 250Mb file size limit (?) – this is only a speculation based on our experiences with OpenAI models’ evolution up to this point. A new whisper model will most likely introduce a higher file size limit.
| Whisper API Audio Limits | |
|---|---|
| Whisper-1 | 25Mb file size maximum |
For the time being, there is a practical solution around this limitation. Developers and API users can split audio files to 25Mb chunks using open source Python libraries such as PyDub and its AudioSegment module.
Training of Whisper:
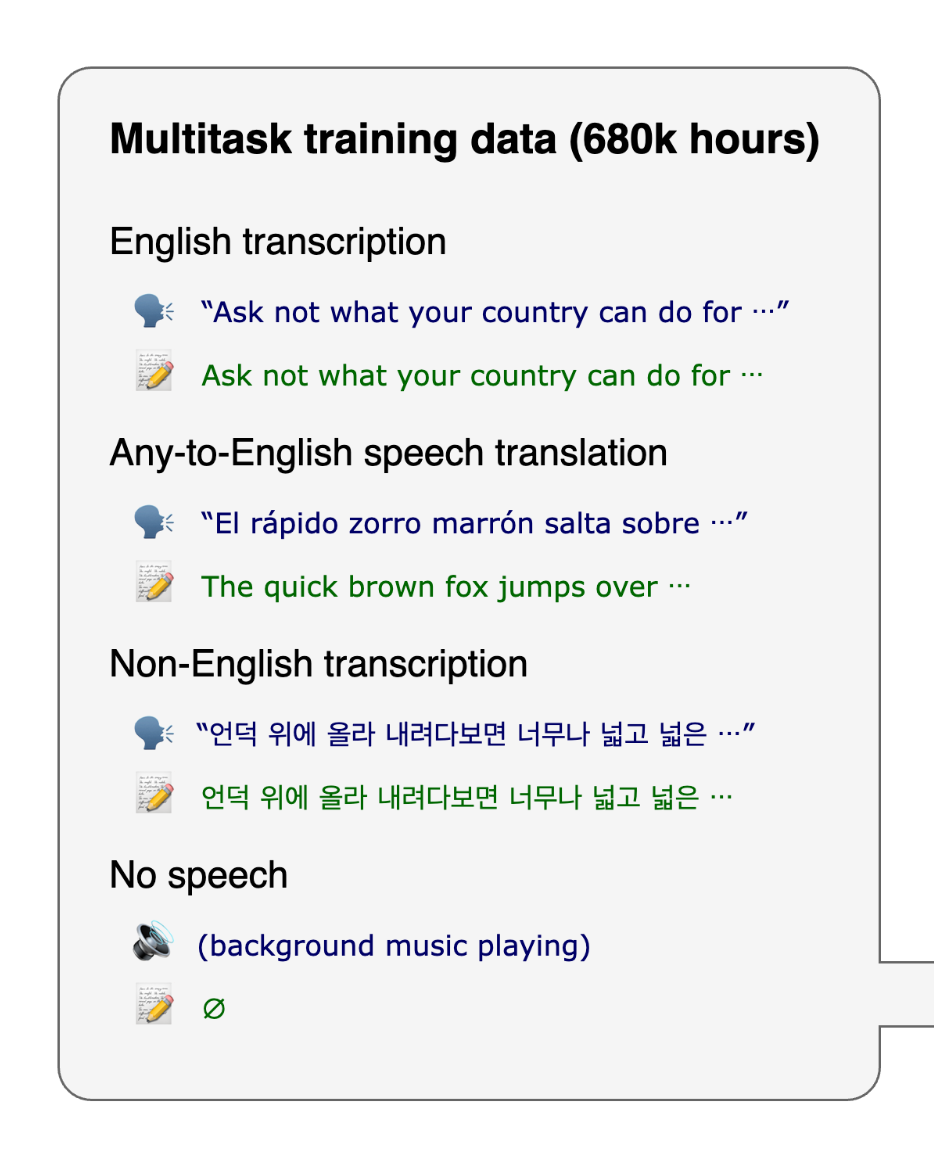
In the 680K hour training of Whisper, its transformer architect was fed with many languages (98+) for transcription and translation purposes.
In addition to various audio data with speech, the model was provided with music without any speech so it can learn not to provide false positive output.
Languages supported by Whisper
Afrikaans,
Arabic,
Armenian,
Azerbaijani,
Belarusian,
Bosnian,
Bulgarian,
Catalan,
Chinese,
Croatian,
Czech,
Danish,
Dutch,
English,
Estonian, Finnish,
French,
Galician,
German,
Greek,
Hebrew,
Hindi,
Hungarian,
Icelandic,
Indonesian, Italian,
Japanese,
Kannada,
Kazakh,
Korean,
Latvian,
Lithuanian,
Macedonian,
Malay,
Marathi,
Maori,
Nepali,
Norwegian,
Persian,
Polish,
Portuguese,
Romanian,
Russian,
Serbian,
Slovak,
Slovenian,
Spanish,
Swahili,
Swedish,
Tagalog,
Tamil,
Thai,
Turkish,
Ukrainian,
Urdu,
Vietnamese,
Welsh.
3- Special AI Use Cases for Whisper
1. Transcription Services: Large businesses and legal, medical, and academic institutions require the transcription of documents daily. With speech-to-text applications, businesses can save their valuable time and money by automating the transcription just by speaking to a device or uploading an audio file.
2. Customer Service: With AI-powered speech-to-text software, customer services teams can convert speech into text and analyze it to determine specific customer demand, complaints or feedback to derive meaningful insights and improve customer retention and customer experience.
3. Education: Speech-to-text transcription can benefit students with learning disabilities, who may have difficulty with writing or keyboarding, by converting speech into text in real-time.
4. Voice-Controlled Applications: Several voice-powered applications, such as voice-controlled virtual assistants like Siri or Alexa, require speech-to-text technology to function effectively.
5. Creating Subtitles/Captioning: Speech-to-text technology is widely used to create subtitles and captions for movies, TV shows, online courses, and presentations.
6. Automated Translation Services: With AI-powered speech-to-text software, converting speech into text in one language can be automated and then translated into multiple languages, streamlining the localization process significantly. Speech-to-Text and in general AI will have a tremendous impact on Travel industry. Check out this interesting article about Future of AI in Tourism.
7. Public Safety: Real-time transcription and analysis of public events, police radio communications, and other sources of audio content can be done with speech-to-text applications, aiding public safety efforts.
8. Healthcare: doctors and nurses can use speech-to-text software while documenting patient information to save them time and prevent human errors.
9. Fast and Convenient Data Entry: This technology can help field agents, reporters, and other workers quickly and conveniently enter crucial data into their systems by speaking their notes rather than typing them.
10. Competitive Advantages for Businesses: Speech-to-text applications can analyze the tone, sentiment, and keywords used in customer interactions, advertising, and social media mentions to drive business insights and identify opportunities for improvement.
It is crucial and very exciting to stay on top of the technological and scientific developments in the field to stay inspired and to be able to produce relevant IT products and services that make our world a more efficient and better place for everyone and seek answers to unknown questions.

Whisper Open Source
| Whisper Open Source Models | Learning Parameter Size | English-only model |
Multilingual model |
|---|---|---|---|
| tiny | 39M | yes | yes |
| base | 74M | yes | yes |
| small | 244M | yes | yes |
| medium | 769M | yes | yes |
| large | 1550M | no | yes |
| large-v2 | yes | no | yes |
Summary
In this Python Tutorial, we’ve continued to explore the latest advancements in OpenAI’s AI models with a focus on their speech-to-text model, Whisper. The newly announced Whisper API endpoint is an exciting opportunity for AI development that will allow developers like us to integrate cutting edge speech recognition capabilities into projects that solve real world problems.
re speech-to-text AI use cases
Whether it’s building voice assistants, transcribing audio files, or creating accessibility tools for those with hearing impairments, the possibilities that Whisper model and its API unlock are truly limitless. We look forward to leveraging this powerful tool to enhance the quality and functionality of our applications. It will be exciting to see the positive impact it’ll have on our visitors and the broader community.
By staying up-to-date with the latest breakthroughs in AI, we can continue to provide the best possible AI tutorials for our users, and help to drive adoption and innovation in the ever-evolving world of programming.